
Machine Learning in Operation
Artificiell Intelligens och Maskininlärning är omfattande områden och eftersom du har hittat denna text är det i perspektivet drift eller Operation som vi tar avstamp.
I en serie inlägg tänkte jag dela med mig av några värdefulla insikter jag kommit fram till och vilka utmaningar du kan stöta på när man investerar i ett Maskininlärnings-verktyg för att jobba proaktivt med drift.
Vad gäller utmaningarna handlar de inte alls om tekniken som man skulle kunna tro. Mer om detta senare.
Seriens inlägg enligt nedan:
- Del 1, Introduktion till Maskininlärning och proaktiv drift
- Del 2, Kultur, förhållningsätt
- Del 3, Processer, arbetssätt
- Del 4, Data, både in och ut-data
- Del 5, Verktyg och exempel
Introduktion till Machine Learning
Maskininlärning (ML) brukar ses som en delkomponent av Artificiell Intelligens (AI) men är i allra högsta grad även ett område i sin egen rätt. ML kan delas upp i flera olika kategorier baserat på om man jobbar med assisterad, förstärkt eller automatisk inlärning.
Då vi utgår från att vi vill börja enkelt och maximera värdet av ML fokuserar vi på automatisk inlärning. Då både AI och ML är heta argument för de flesta leverantörer att sälja sina lösningar och produkter möter vi tyvärr många som även kopplar statiska matematiska algoritmer till området. Det finns absolut användning för detta också i många fall men det som verkligen skiljer sig är själva inlärningen. Att baserat på data justera algoritmerna för att bli så bra som möjligt på att förutse eller tolka data.
Hur funkar det?
Förenklat kan man säga att maskininlärning går ut på att ’träna’ ett system på en känd mängd data där systemet själv justerar sina algoritmer för att komma så nära en bra förutsägelse som möjligt. När sedan algoritmen börjar stabilisera sig kan systemet börja applicera det den har lärt sig på nytt data.
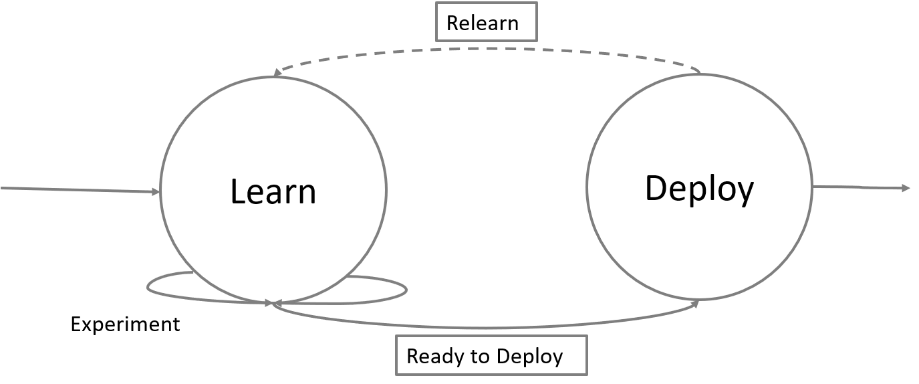
Är allt som heter Maskininlärning lika bra?
Nej verkligen inte! Det är just här som vi ser stora skillnader i olika produkter. Många system har mellan 10 och 20 olika typer av algoritmer som kan appliceras på varje mätvärde. Men alla lämpar sig inte till alla olika typer av data. Om man använder fel algoritm till fel typ av data kommer den fortfarande vara väldigt rörlig eller rörig när den tycker att inlärningen är klar. Det vanligaste tecknet på detta är att du får alldeles för mycket larm s.k. false-possitives, utfall som systemet anser vara onormala men inte är det, och risken är stor att det blir vargen-kommer av din investering.
Till exempel, om du tittar på ett system och du förväntas själv att välja vilka algoritmer du vill ha för ett specifikt mätvärde måste du fundera på om ni har resurser och kompetens för att göra det, på kanske tusentals parametrar och över tid?
Maskininlärning i IT Operation
Jag har fortfarande inte hittat ett verktyg som är bra på allt, att förlita sig på att de verktygen man redan har i sin miljö också nu kommer med en bra ML lösning kan visa sig kostsamt.
Det vi vill se är ett system eller verktyg som kan läggas på toppen och användas på det data som du redan har.
När vi pratar om ML-data är det främst tidsserie data, statistik över tid, som avses. Du har säkert redan att antal olika monitoreringssystem som samlar på detta. SCOM, Nagios, AppDynamics, Splunk, ITM och OP5 är bara några exempel och gemensamt är att alla dessa samlar in mängder av data.
Genom att föda detta data från de olika systemen till en gemensam, överliggande ML-lösning kommer du dels att kunna välja ett ML system som är bra på just ML men det kommer även att kunna hitta relationer mellan dina olika system och de teknikdomäner de övervakar.
Det andra vi vill se är att ML-systemet själv avgör vilka algoritmer som passar för dina olika mätvärden och har en bra utvärderingsmodell för att säkerställa att de algoritmer som används är tillräckligt tränade innan de går i produktion.
ML-systemen behöver mål att utgå ifrån och i vår driftsituation är målet att öka tiden mellan avbrott (MTBF) samt minska tiden att felsöka (MTTR).
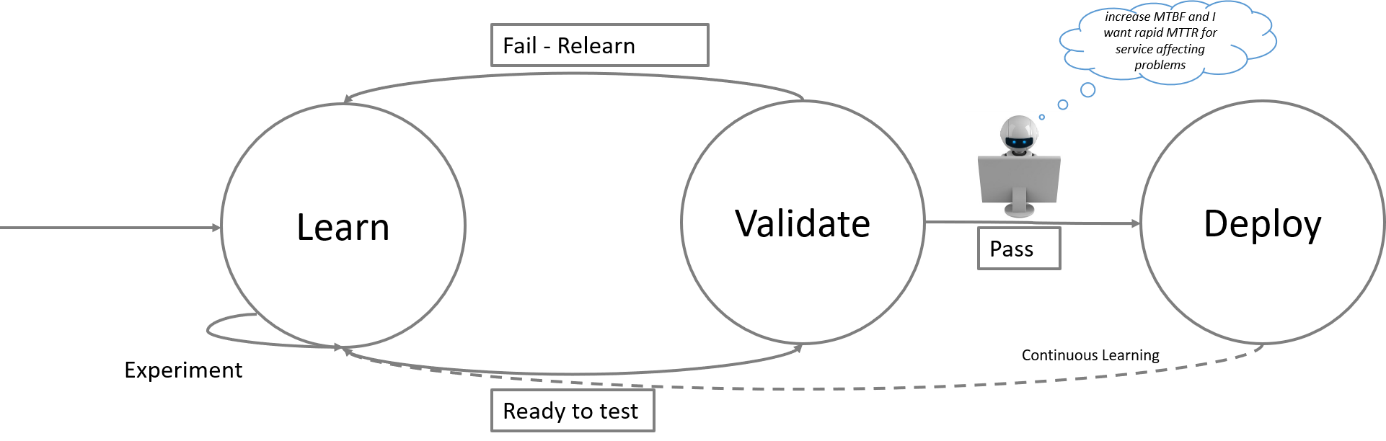
Dessutom skall systemet ge dig insikter du inte redan hade. Att till exempel kunna relatera helt olika mätvärden till varandra i flera dimensioner. Det vi vill är att få mer träffsäkra larm. Rätt information till rätt mottagare i rätt tid.
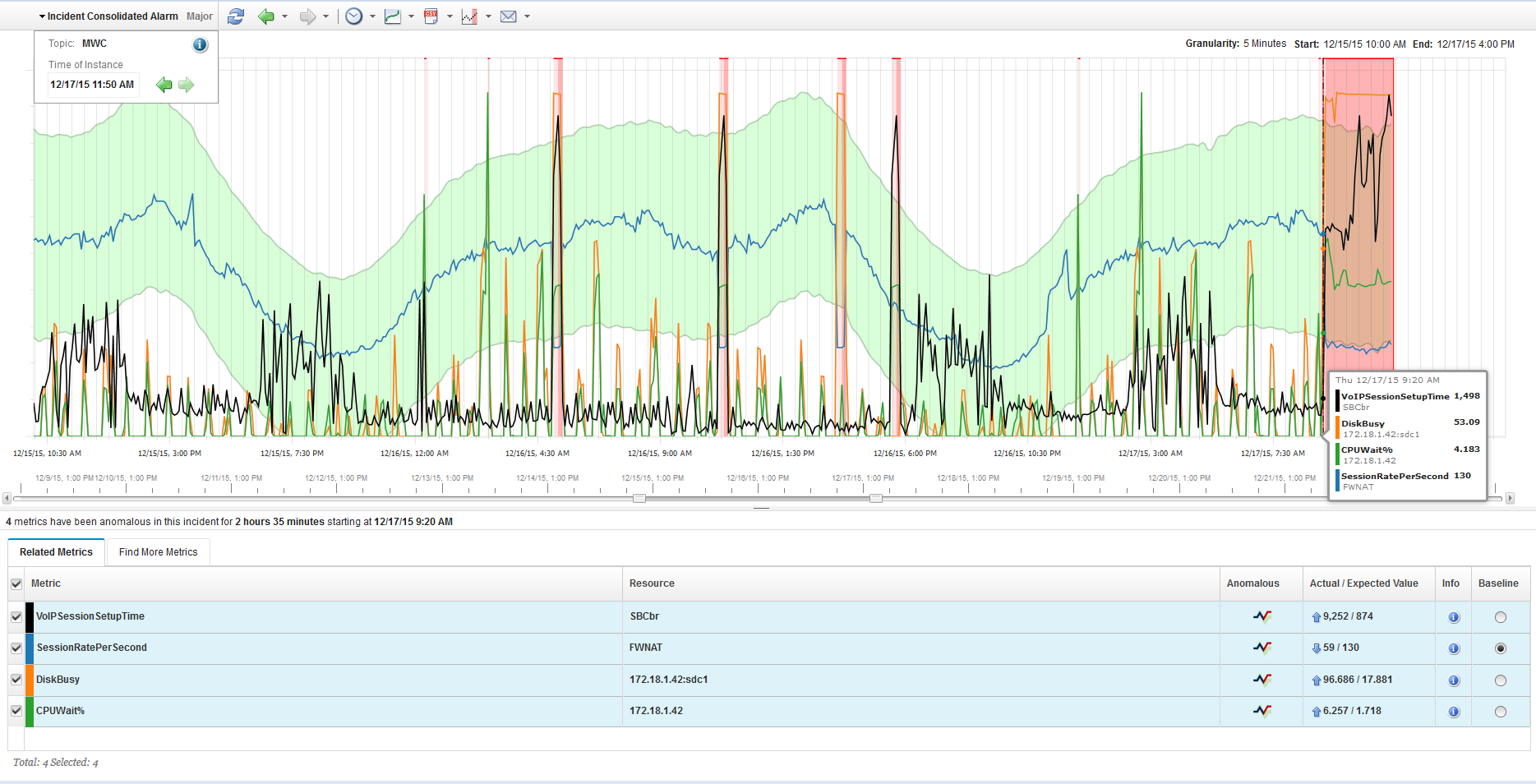
Utmaningar
Jag lovade att återkomma till vilka utmaningar som finns i att implementera maskininlärning i din Operation. Det är inte tekniken som är utmaningen, det är att få ut det reella värdet av ML-lösningen och bli proaktiv. Här ligger utmaningen i förändring av arbetssätt – processer och förhållningssätt – kultur.
Hur ska man få resurser och investeringar för att avhjälpa fel som inte har inträffat än?
Eller, när du ser att problemen som egentligen är symptom behöver avhjälpas inom ett helt annat område, som inte tycker sig ha några problem. Detta kan riskera att bli den riktiga utmaningen.
Att organisationen och ledningen får förtroende för de proaktiva insikter och larm som din ML lösning ger blir helt avgörande för att värdet skall kunna realiseras. Att verkligen bli en driftorganisation som agerar proaktivt.
Alla fel kommer inte att försvinna men att ge resurser och uppmärksamhet till de som motverkar avbrott innan dom inträffar när du samtidigt ska släcka bränder. Det är den nya balansakten som behöver hanteras.
Och så en fråga jag fick häromdagen. Hur fungerar proaktiv operation i ITIL?
Men mer om det nästa gång…
Slutligen, tveka inte att höra av dig om du vill veta mer!

