
Machine Learning in Operation – Verktyg och exempel
Seriens inlägg enligt nedan:
- Del 1, Introduktion till Maskininlärning och proaktiv drift
- Del 2, Kultur, förhållningsätt
- Del 3, Processer, arbetssätt
- Del 4, Data, både in och ut-data
- Del 5, Verktyg och exempel
Artificiell Intelligens (AI) och Maskininlärning (ML) är omfattande områden. I denna avslutande del i denna artikelserie ska vi titta på verktyg och ett exempel på en implementation för proaktiv drift.
Det finns flera kategorier av ML-verktyg som idag kan vara aktuella när det kommer till IT Operation och proaktiv drift. Vi kommer inte att gå igenom specifika verktyg utan titta på några olika kategorier och vad som kan vara värt att tänka på.
Som jag skrev i början av denna artikelserie. Alla verktygsmakare använder Artificiell Intelligens och Machine Learning som marknadsföring idag. Men som vi också tittat på så finns det många olika aspekter och varianter på AI/ML och tyvärr använder mindre nogräknade företag dessa attribut fastän det inte ens är AI/ML utan enklare matematiska algoritmer under huven.
Den generella rekommendationen är att utvärdera. Se om den föreslagna lösningen verkligen passar er. Speciellt i detta område är det väldigt svårt att förstå hur en lösning kommer att fungera i just er miljö utifrån en PowerPoint.
Olika typer av lösningar
Inbyggd AI/ML. I princip alla verktygsmakare på marknaden idag har eller kommer med en modul eller funktion de kallar AI eller Machine Learning. Här finns det stor risk att bli lurad eller åtminstone inte få det man förväntar sig. Tänk på att en av de viktigaste funktionerna är att inte bli översvämmad med larm. Något som kan vara ett tips att titta efter är att man har optimerat ML modulen för det specifika ändamål verktyget är skapat. Ex. applikationsövervakning eller liknande.
Observera att det finns inget som hindrar att man använder ML i flera olika verktyg eller på olika nivåer i verktygsstacken. Tyvärr har jag sett exempel där man låser fast sig vid ett verktyg och sedan försöker få det att göra sådant det inte är avsett för.
Tre punkter att tänka på för att få rätt förväntningar eller ta rätt beslut om investering.
- Endast de parametrar som just detta verktyg samlar kommer att vara tillgängliga för ML. Ex. om det är applikationsövervakning så kommer inte verktyget ta hänsyn till underliggande infrastruktur eller ha ML för nätverk.
- Är det verkligen ML? Hur fungerar själva inlärningsprocessen och finns det någon validerings funktion? Att rätt algoritmer används till rätt data. Se upp med verktyg där du själv väntas veta vilken algoritm som ska användas till vad. Om det inte är det du är ute efter.
- Kan ni växa i denna lösning? Det kanske är ett alldeles utmärkt sätt att starta, men kommer ni orka byta system när ni växer ur det?
Generisk AI/ML
Det finns flera otroligt kompetenta lösningar på marknaden där man kan bygga sina egna ML flöden och utvärderingar. Ett exempel är Watson Studio. Även om det grafiska gränssnittet är lockade så är ML inte helt enkelt utan experthjälp. Med rätt kompetens och mycket tid kan man göra i det närmaste otroliga saker, men är det där ni ska ha er kompetens? Om ni väljer den vägen så skulle jag vara väldigt nyfiken på att se vad ni lyckas skapa.
- Har ni tid att utveckla och framför allt förvalta lösningen?
- Har ni tillgång till kompetensen. Att både vara expert inom ML och drift är inte så vanligt?
Data-Lake verktyg
Jag har nu sett flera verktyg som har sin produkt inriktad på Big-Data eller Datalakes som också har lagt till AI/ML. Detta ser mycket lockande ut men några punkter kan vara värt att tänka på och utvärdera.
- Är verktyget anpassat för era målsättningar. Hur mycket utveckling krävs och hur skall förvaltningen skötas?
- Data kostnad. De jag hitintills sett kräver även att det data som skall behandlas lagras i deras lösning. Det är här kostnaderna uppstår. Även om jag förespråkar att man skall tillgängliggöra information på ett enkelt sätt för Operation utan att behöva leta i underliggande system så tänk på detta
- Är det ML och hur bra är den? Bara för att det är ett utmärkt verktyg för datalagring och visualisering. Är det en bra lösning för ML? Samma punkter som under ”Inbyggd AI/ML” gäller alltså
Fristående ML lösning
Dessa lösningar är byggda för att använda det data du redan har i dina olika verktyg. Processa det och generera resultat. Ofta innehåller de bara den senaste tidens data, för fokus ligger på algoritmerna och att processa det senaste datat mot dessa. Detta gör att man kan använda billiga (eller dyra) lösningar för att samla in och lagra data medan produkten är framtagen för just detta ändamål samtidigt kan flexibilitet och förmågan att täcka allt från nät till applikation kan kännas något komplicerat.
Men några saker är viktiga att titta på
- Hur samlar vi in data. ML lösningen gör det inte åt dig. Är datat av bra kvalitet och kan vi göra det tillgängligt för ML systemet?
- Samma som föregående. Är det verkligen ML och ger det värdet vi eftersöker?
Det framgår säkert tydligt vilken typ av lösning jag själv förespråkar. Det är ingen hemlighet att jag gillar flexibilitet och alltid blir misstänksam när någon hävdar att deras verktyg är bra på alla saker, samtidigt.
Men för att förtydliga varför jag förespråkar ett ML ”på toppen” som kan ta data från många olika källor såsom din nätverksövervakning, din serverövervakning och din applikationsövervakning.
Det första är korrelation. Att vi genom detta verkligen kan använda ML för att hitta relationer mellan olika teknikdomäner i vår miljö. Att exempelvis kvaliteten på nätverkstrafiken korrelerar med svarstiderna i en applikation eller att minnesutnyttjandet relaterar till databaslåsningar.
Det andra är driftmiljön. De som jobbar i första och andra linjen skall på max 3 klick hitta det data som ligger till grund för ett larm. Då kan man inte ha en massa olika verktyg man ska logga in i och ha kompetens på samtidigt som dessa underliggande verktyg kan vara avgörande för 3:e linjen.
För att beskriva det ytterligare tänkte jag visa ett exempel och samtidigt avsluta denna artikelserie med det roligaste. Ett exempel på en implementation.
För att kunna visa omaskerade skärmbilder är detta taget från vår egen demomiljö och jag kommer inte bara att beskriva själva ML-systemet utan även hur vi knyter in det i vår (figurativa) första och andra linjes konsoler för en proaktiv drift.
Vad satte vi då för mål i vårt Operation Center?
Vi vill snabbt kunna utföra en triage, att verifiera larmen för att prioritera och eskalera till rätt mottagare med rätt prioritet direkt från konsolen. (ni kommer ihåg? max 3 klick)
De larm som driften själva kan gå vidare med går då till 2:a linjen som på samma sätt men med djupare kunskap skall isolera felet och utföra eller beställa nödvändig förändring från 3:e linjen.
Hela tiden men fokus på ’Shift-Left’ att så mycket som möjligt skall utföras så tidigt som möjligt i kedjan.
För att få data till detta behöver vi fyra olika typer av data från vår miljö vi ska ha ansvaret för:
- Event – vanliga traditionella event om status förändringar och definierade händelser i vår miljö
- Loggar – meddelanden och information om vad som pågår
- Mätdata – statistik över olika mätpunkter. Last, svarstider, utnyttjandegrad, o.s.v
- Meta-Data – dokumentation, Asset, Config, Change, Knowledgebase, SLA, mm
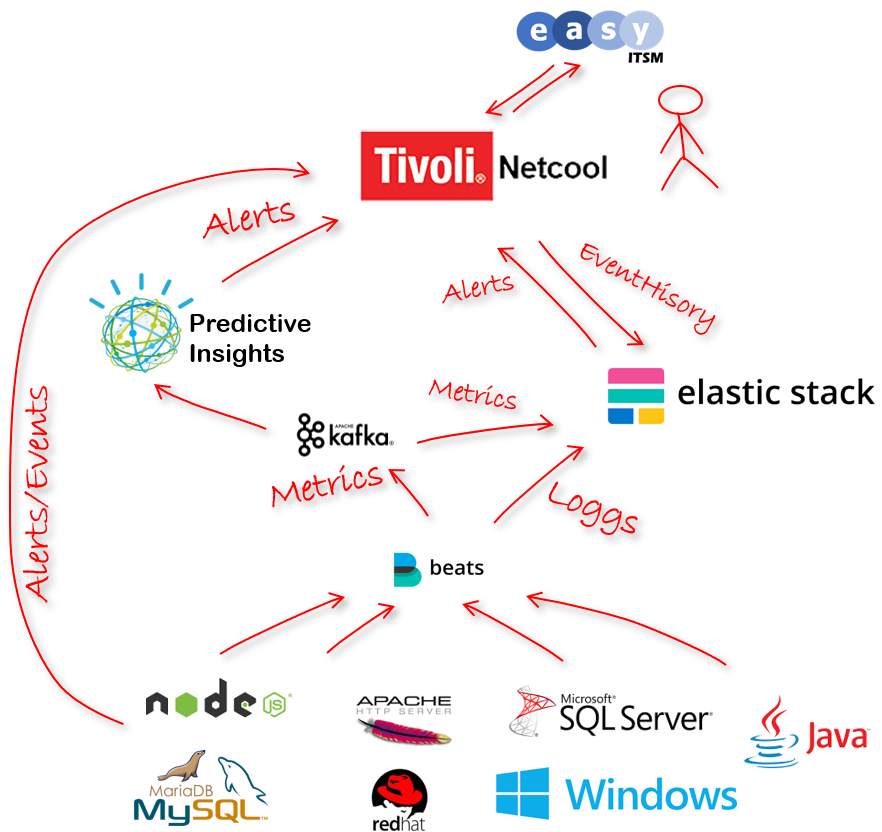
Lösningen vi använder i vår demo miljö för att åstadkomma detta består av serveragenter från Elastic. Både MetricBeats och FileBeats för att fånga mätdata och loggfiler. Både loggfiler och metrics lagrar vi i ElasticSearch men innan vi stoppar in mätdatat kör vi det via Kafka. Här splittras datat. En ström fortsätter till ElasticSearch och en kopia skickas till Predictive Insight (PI), en ML lösning som från början bygger på IBMs Watson teknologi men som nu är specialiserad på tids-series data för Operation. Både reaktiva larm direkt från infrastrukturen, ML-larm från PI och logg-larm från Elastic skickas sedan upp till vår eventhanterare Netcool där vår 1st och 2nd Line ’jobbar’. Fullt integrerad med vår ITSM för Incidenthantering och CMDB data, naturligtvis.
Byt bara ut produkt-namnen mot de som du har i din miljö så känner du kanske igen dig.
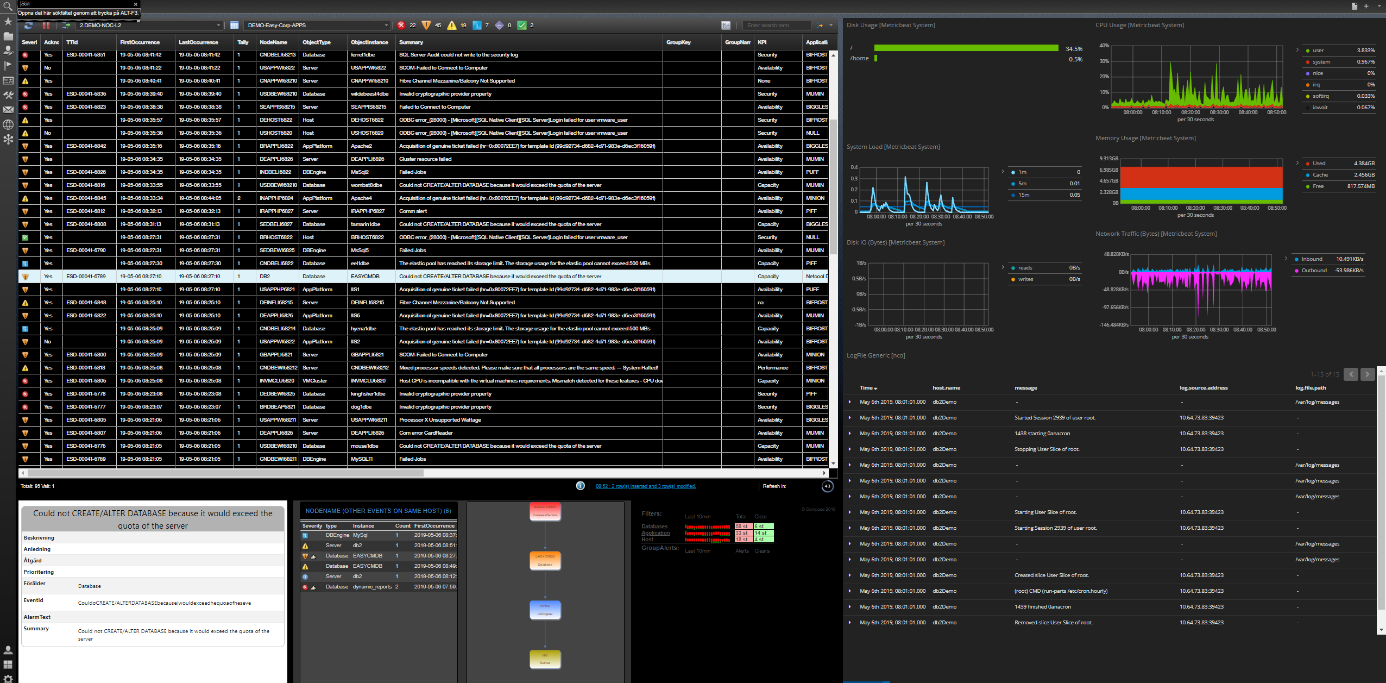
För att visa ett enkelt exempel på proaktiv drift kikar vi först på hur vår andra line-konsol ser ut.
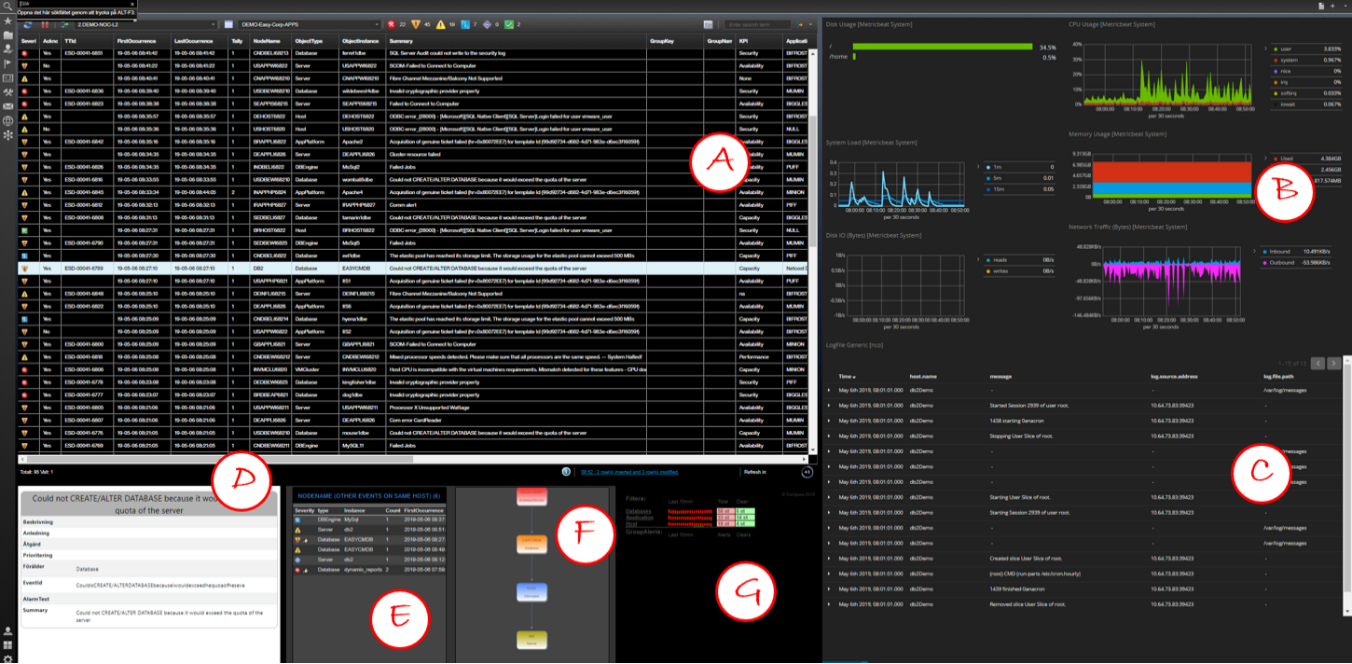
2nd line konsol
- (A) Eventlistan med de event som har filtrerats fram för 2nd line. Larmen prioriteras baserat på SLA, produktionsstatus, change och system
- (B) Dashboard som visar de vitala mätvärden för det objekt som markeras i listan och för den tidsperiod som larmet gäller. Om larmet kom in för två timmar sedan och avslutades 25minuter senare är det den tiden +- 30min som visas så fort larmet markeras
- (C) Logg från det objekt som markeras i larmlistan med urvalet för tid på samma sätt som ovan
- (D) Under larmlistan har vi vår kunskapsdatabas för larmen. Igen, så fort ett larm markeras hämtas motsvarande instruktion
- (E) Sedan en sammanfattning av andra larm på samma Nod under samma tid. Även om vi har både ML och event-korrelering kan det vara värdefullt att se om det finns andra larm eller incidenter på den Nod jag undersöker
- (F) En topologisk bild över hur det objekt som är markerat hänger ihop med andra objekt, detta hämtas från CMDB samt färgsätts om dessa objekt har aktiva larm
- (G) En lista över större pågående situationer för att veta om det är något som det du tittar på kan vara relaterat till. Tillexempel större nät-fel eller strömavbrott
Vi får återkomma till alla dessa funktioner en annan gång. Vi skulle ju titta på proaktiv drift och maskininlärning.
Data från våra MetricBeats skickas in i Predictive Insight. Där lär systemet sig på data. Sedan valideras resultaten och endast de algoritmer som passar för just det enskilda mätvärdet passerar och används sedan i drift. Inlärningsprocessen kan ta allt från något dygn till ett par veckor. Det är sedan en pågående process och algoritmerna förfinas hela tiden.

Vi har fått ett proaktivt larm från vår maskininlärning!
Från larmet kan vi se att det är på vår ElasticDemoA Server som har ökat sitt minnesanvändande på ett onormalt sätt.
Vi pausar lite här.
Beroende på vilken roll du har som läser detta infinner sig nu säkert några olika scenarier.
Som tekniker är det lätt att tänka. Mäh! Det hade jag ju sett i direkt. I perfmon (eller liknande). Helt riktigt, men då hade du ju redan letat efter något som var fel. Det här är det första vi ser av denna situation, ingen har ringt eller klagat!
Det andra är att PI säger att detta är ’onormalt’ beteende. För att se det utan ML behöver man känna denna server och vara bekant med hur den brukar bete sig. Det är inte driftpersonalen, dom har några tusen servrar att bry sig om.
Om Du är tjänsteansvarig kanske du tänker: – Men det betyder väl inte att något är trasigt eller vad är påverkat – märker min kund det här?
I ett vältrimmat system så borde svaret vara ’nej’ på bägge frågorna för detta är ju ett proaktivt larm. Det ska ge oss tid att agera innan något går sönder eller någon märker av det.
Till slut, om du jobbar med drift kliar det nu säkert i fingrarna för att klicka på larmet och se grafen som visar minnet på den maskinen och hur har PI har kommit fram till detta?
För hur ska du kunna lita på larmet och ha förtroende för ett system som jag bara skriver om här?
Tillbaka till driften
Åter till vårt larm och just detta med förtroende. När man har mognat och fått förtroende för sitt data och sitt ML-system borde man här gå direkt till att undersöka trolig orsak till detta onormala beteende. Att helt enkelt lita på att ML lösningen har rätt och inte ägna tid åt att överpröva och göra sin egen bedömning men att nå det tar en del tid som vi tittade på i ’kultur’ avsnittet.
Men okej då, vi är nya här. Vi vill se hur PI har beräknat detta. Vi offrar några klick…
Högerklick på larmet och väljer vår ML graf.

Här ser vi tydligt hur minnes-utnyttjandet varit väldigt stabilt och helt plötsligt hoppar upp en bra bit. PI har dessutom sett att antalet TCP-paket är relaterat och kan vara ’probable-cause’.
Hmm. Vår ElasticSearch-server får plötsligt mer trafik och minnet sticker iväg…
Vi återvänder till vår konsol och tittar på vår Servers mätvärden. De vi redan hade uppe till höger på skärmen alltså (inte ens ett enda klick)
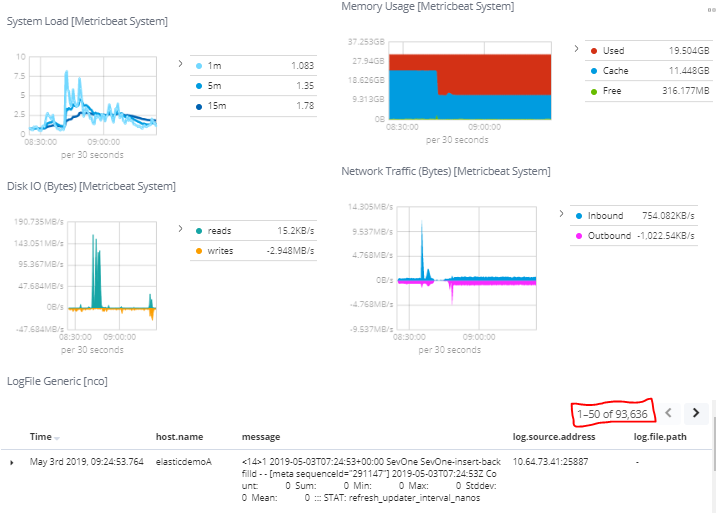
Här ser vi att utnyttjandet av minnet ökar kraftigt. Nu kan man undra varför vi inte hade den förra grafen från PI i detta fönster?
Det hade varit snyggt men som jag nämnde tidigare, alla verktyg är inte bra på allt och PI’s grafer är för stora och något långsamma för att visas på detta sätt men det är samma data vi tittar på som PI använder via vår ’splitt’ i Kafka.
Nu vill vi veta vad som har hänt och vänder blicken mot loggfilen från samma Server. Vi ser att vi har knappt 100 000 logg rader!
En snabb markering av just den exakta tiden då minnet ökade.

Då har vi 78 rader. Klart bättre. Vi har lite tur och ser i det andra medelandet att någon har lagt till en ny källa till ElasticSearch. I detta fall ett system som heter SevOne.
Probable-cause
Vi vet att en onormal förändring skett i vår miljö på Server ElasicDemoA.
Vi vet vad som har hänt – en ny källa har lagts till.
Vi har hittat vår orsak.
Nu kan vi göra en proaktiv åtgärd!
Även här får vi en viss skillnad i både arbetssätt (process) och förhållningssätt (kultur).
Som drifttekniker behöver du nu ta kontakt med kunden eller systemägare för att berätta att något hänt som de inte vet om och som dessutom de inte märkt av och som grädde på moset kan driva deras kostnad för systemet.
Här gäller det att bygga även deras förtroende och att kommunicera tydligt.
Rätt utfört kommer detta i längden att inte bara att öka förtroendet för driften utan hela IT-avdelningen.
Att säkerställa att du har ett systemstöd även här för att underlätta denna kommunikation genom exempelvis rapporter eller mallar rekommenderas.
Det är lätt att glömma denna del men om organisationen inte får förtroende för er proaktiva ansats så kommer den tyvärr att snart bli bortprioriterad och Ni riskerar att hamna tillbaka i brandsläckning och att prioritera den som skriker mest.
Tänk på att det tar tid att bygga förtroende men bara ett ögonblick att rasera det.
Hoppas att du har fått någon känsla för hur du kan bli proaktiv i din drift och att maskininlärning är både enkelt och svårt, men inte där man kanske först tror.
Vi på Compose IT har lång erfarenhet av både drift och verktyg för att detta.
Vi kommer gärna och berättar mer om hur vi kan hjälpa just Er organisation utifrån era mål förutsättningar.

