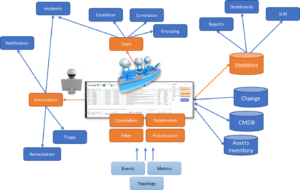
Integration av CMDB är en självklarhet inom Operations Management
Att sköta driften av våra IT miljöer kan låta som en enkel och etablerad funktion, men IT är ett rörligt mål. Det pågår hela tiden förändringar, både planerade oplanerade.
Som tur är, finns det ingen annan verksamhet där det är lika enkelt att mäta prestanda, kapacitet och att samla in larm som i en IT miljö. Utmaningen är att förstå vilka larm och vilken information som är viktig och som säger att ett problem uppstått och att det krävs en åtgärd.
Genom att integrera och dela information mellan tekniskt fokuserade övervakningssystem, processrelaterade ITSM verktyg samt din strukturerade information i form av dokumentation, CMDB, Asset eller kanske en Excel lista(?) kan du injicera förståelsen om vad som är viktigt och vilka händelser som är ofarliga och vilka som är kritiska incidenter.
Detta är grunden för en proaktiv drift och i förlängningen med maskininlärning få en AIOps plattform på plats.
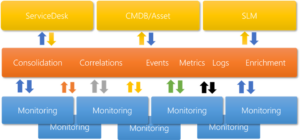
Watson AIOps är i grunden en integrationsplattform, att ta emot information i form av event, larm och statistik har alltid varit grunden. Att sedan integrera till andra system för att berika dessa larm med information om kund, SLA, placering och driftstatus för att kunna prioritera och hantera larmen effektivare är inte alltid lika självklart.
Att det dessutom enkelt går att integrera till Incident, Change och CMDB är kanske inte lika känt.
Som konsulter på Compose IT jobbar vi med Netcool/Watson AIOps hos många olika kunder i hela Norden och möter där varierade miljöer och lösningar för ITSM och dokumentation. Även inom samma organisation kan dokumentation och incidenter hanteras i olika system. Nätverk har sitt sätt att dokumentera, DevOps grupperna använder kanske Jira och Datacenter kör ServiceNow.
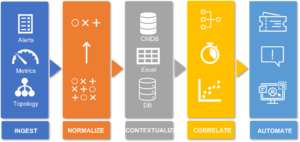
Oavsett vilka verktyg som används är behoven av så bra larm och incidenter som möjligt gemensamma. Att börja felsöka en ’felaktig’ incident är bara slöseri med tid som hade kunnat användas till något annat.
Hos alla våra kunder har vi i varierande grad och oberoende av vilka verktyg eller plattformar de har integrerat Event processen (larm hantering) till kringliggande processer för att avgöra om ett larm är riktigt, är det viktigt och vem ska det eskaleras till i form av en Incident eller Request?
Typiska integrationsperspektiv:
CMDB/dokumentation
För att veta om ett larm från en utrustning är viktigt kan man inte bara titta på larmet utan man behöver också veta vilken roll denna utrustning har. Är det test, utveckling eller produktion? Är det en core-switch eller en CPE? Vem är ansvarig och vilket system tillhör den, finns det ett SLA?
I vissa fall vänder vi även på integrationen och föder CMDB med information från övervakningsverktygen då de ofta innehåller mycket information om de objekt som övervakas.
Change
När man vet vad det är för utrustning, vem som är ansvarig och att det är ett allvarligt larm behöver man veta om denna situation, exempelvis en databas som är nere, är den nedtagen för att uppdateras eller har den gått ner på grund av ett fel? Genom att integrera med Change-processen kan vi undertrycka larm som kommer under ett pågående arbete. Detta hindrar även att någon automation går in och försöker återstarta databasen medan uppdatering pågår. Vilken i sin tur kan hindra ytterligare allvarliga problem.
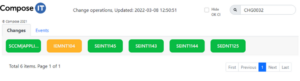
Man kan visa larmstatus för de enheter som ingår i ett change så att den som utför change kan verifiera att allt är ’grönt’ innan man avslutar sitt change. På detta sätt sparar man mycket tid genom att slippa felaktiga incidenter.
Incident
Att skapa en incident via larmlistan är en sak men att nyttja en dubbelriktad integration så att Incident och larm kan fortsätta att kommunicera automatiserar delar i både event och Incident processen. När ett larm har eskalerats till en Incident och det fortsätter att komma in information adderas detta till incidenten. Om sedan situationen återställs och larmet avslutas stängs Incidenten automatiskt. Eller tvärt om, när Incidenten stängs avslutas larmet. Detta ser till att spara mycket tid och undviker att både incidenter och larm ligger kvar i onödan.
Exempel på integration mellan COP/WatsonAIOps och ServiceNow:
Vid förändringar i CMDB skickas dessa via REST till COP och där upprätthålls en datamängd för att berika larmen. Vi följer relationerna i CMDB data för att automatiskt identifiera vilket eller vilka system/business services som en utrustning hör till för att få fram SLA, och om det är test/utveckling eller produktionsmiljö. Detta gör att alla event kan berikas med aktuell information.
Efter detta använder vi REST/API för att kontrollera om det finns ett pågående change på en larmande utrustning. När så är fallet undertrycker vi detta larm så det inte visas för driften eller automatiskt skapar en Incident. Om larmsituationen kvarstår när change är klart skapas en incident automatiskt.
Incidenterna kan skapas manuellt från larmlistan eller automatiskt via regelverket i Dynamic Event Management. Detta sker via REST/API till ITSM verktyget och incidenten läggs på ansvarig grupp, med korrekt prioritet. Efter att Incidenten är skapad kommunicerar COP till ITSM eller vice versa om status förändras eller ytterligare information finns att skriva till incidenten, exempelvis automation av Ansible. Vissa applikationsrelaterade larm skickas inte till ITSM utan skickas till Jira via webhook som används för case-magement av utvecklarna.