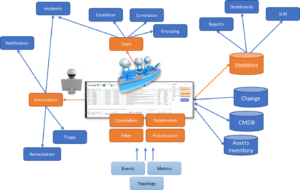
Integration of the CMDB is a matter of course
Integration of CMDB is a matter of course in Operations Management
Managing the operation of our IT environments may sound like a simple and established function, but IT is a moving target. Changes are constantly taking place, both planned and unplanned.
Fortunately, there is no other business where it is as easy to measure performance, capacity and to collect alarms as in an IT environment. The challenge is to understand which alarms and which information are important and which indicate that a problem has occurred and that an action is required.
By integrating and sharing information between technically focused monitoring systems, process-related ITSM tools as well as your structured information in the form of documentation, CMDB, Asset or perhaps an Excel list(?), you can inject the understanding of what is important and which events are harmless and which are critical incidents.
This is the basis for a proactive operation and, by extension, with machine learning, get an AIOps platform in place.
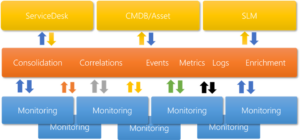
Watson AIOps is basically an integration platform, receiving information in the form of events, alarms and statistics has always been the basis. Then integrating into other systems to enrich these alarms with information about the customer, SLA, location and operational status in order to be able to prioritize and manage the alarms more efficiently is not always as obvious.
The fact that it can also be easily integrated into Incident, Change and CMDB is perhaps not as well known.
As consultants at Compose IT, we work with Netcool/Watson AIOps at many different customers throughout the Nordics and encounter varied environments and solutions for ITSM and documentation there. Even within the same organization, documentation and incidents can be handled in different systems. Networks have their way of documenting, DevOps groups may use Jira and Datacenters run ServiceNow.
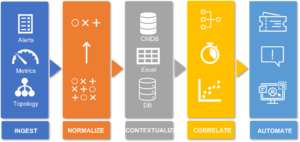
Regardless of which tools are used, the needs for as good alarms and incidents as possible are common. Starting to troubleshoot a ‘wrong’ incident is just a waste of time that could have been used for something else.
With all our customers, we have to varying degrees and regardless of which tools or platforms they have integrated the Event process (alarm handling) into surrounding processes to determine whether an alarm is real, is it important and to whom should it be escalated in the form of a Incident or Request?
Typical integration perspectives:
CMDB/documentation
To know if an alarm from a piece of equipment is important, you can not only look at the alarm, but you also need to know what role this piece of equipment has. Is it test, development or production? Is it a core switch or a CPE? Who is responsible and which system does it belong to, is there an SLA?
In some cases we also reverse the integration and feed the CMDB with information from the monitoring tools as they often contain a lot of information about the objects being monitored.
Change
When you know what equipment it is, who is responsible and that it is a serious alarm, you need to know about this situation, for example a database that is down, is it down for updating or has it gone down due to an error ? By integrating with the Change process, we can suppress alarms that come during a work in progress. This also prevents any automation from stepping in and trying to restart the database while updating is in progress. Which in turn can prevent further serious problems.
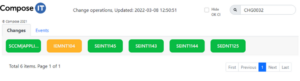
You can show the alarm status of the units that are part of a change so that the person performing the change can verify that everything is ‘green’ before ending their change. In this way, you save a lot of time by avoiding incorrect incidents.
Incident
Creating an incident via the alarm list is one thing, but using a two-way integration so that Incident and alarm can continue to communicate automates parts of both the event and the Incident process. When an alarm has been escalated to an Incident and information continues to come in, this is added to the incident. If the situation is then restored and the alarm is ended, the Incident is automatically closed. Or vice versa, when the Incident is closed, the alarm ends. This saves a lot of time and avoids that both incidents and alarms remain unnecessarily.
Examples of integration between COP/WatsonAIOps and ServiceNow:
In the event of changes in the CMDB, these are sent via REST to the COP and a data set is maintained there to enrich the alarms. We follow the relationships in the CMDB data to automatically identify which system/business services a piece of equipment belongs to in order to obtain the SLA, and whether it is a test/development or production environment. This means that all events can be enriched with current information.
After this, we use REST/API to check if there is an ongoing change on an alarming device. When this is the case, we suppress this alarm so it is not shown to the operation or automatically creates an Incident. If the alarm situation persists when the change is complete, an incident is created automatically.
The incidents can be created manually from the alarm list or automatically via the regulations in Dynamic Event Management. This is done via REST/API to the ITSM tool and the incident is assigned to the responsible group, with the correct priority. After the Incident is created, COP communicates to ITSM or vice versa if the status changes or additional information is available to write to the incident, for example automation by Ansible. Some application related alarms are not sent to ITSM but sent to Jira via webhook used for case management by the developers.