
Organize data with Elastic Ingest Pipeline
Transforming and processing data before indexing is a very useful feature of Elastic. This can be done using the Ingest Pipeline tool, which makes it both easier and smoother. After processing the data, the transformed documents are added to a data stream or index. It is possible to create and manage these pipelines using the Ingest API or through Kibana. What is required to gain access to this function is that at least one node in the Elastic cluster is an “ingest node”, that parameter is also set by default when the Elastic stack is set up.
Benefits of Ingest Pipeline
The advantages of Ingest Pipeline are that you easily get a clean and structured index and the user-friendly GUI. Furthermore, the possibility to simulate and to apply an error handling through ‘fail’ processor.
What is a Pipeline?
A pipeline is, in short, a JSON document consisting of a description and one or more processes. Each process is executed in the order it is defined, there are several built-in processes to use. The description ‘Description’ is not necessary but is a good way to describe and list what is happening in your pipeline. It gives a good structure.
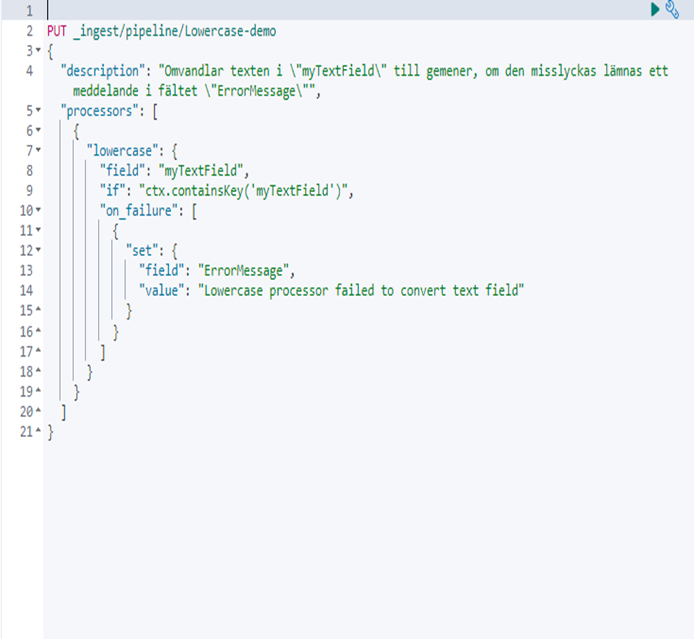
An example of process is ‘Lowercase’ which converts a string to the corresponding lower case. If the field is an array of strings, all members of the array will be converted. In all these processor types, conditions can be set that define when the procedure should be executed. This is written in ‘Painless’ either inline or as a stored script.
Another example is how to handle inaccuracies in the pipeline. Pipeline executes sequentially and stops at the first exception, which is not always desirable.
By setting the ‘on-failure’ parameter, a list of what to run immediately after a failure is defined. You can use this parameter both at the processor and at the pipeline level. In this way, you can encapsulate error handling for analysis and thus get a better designation.
In Elastic, there are two approaches to generating a pipeline:

There is no difference between what you can do in the API or Kibana’s interface, it is rather a matter of taste how you choose to work. Another good feature is simulation. By simulating the pipeline, you can test the process before it is used in production. To perform a simulation, a document is required, either an existing one defined with ‘id’ or a new document is written manually in the simulation question.
To connect a pipeline to an index, it is necessary to add a line to the index’s settings:
‘Index.default_pipeline : <– name of pipeline –>’.
To apply the pipeline to an existing index and affect documents that already exist, ‘reindex’ is used.
‘_update_by_query?pipeline=<– name of pipeline –>’

